NLP with Topic Modelling

Understanding why we use Topic Modelling with easy implementation

Photo by Kelly Sikkema on Unsplash
There’s too much data today and there will be too much data in the future by a factor of a thousand. — Ben Hoffman
Why Topic modelling
Topic Modelling is mainly used to reduce the high dimensionality of features present in Natural Language Processing models allowing us to grasp and use only the main topics.
What is high dimensionality?
In brief, high dimensionality deals with the occurrence of the presence of data points that are closer to the boundary of our sample space. This proves to be a problem, as, predictions are much more difficult near the edges of the training sample. One must extrapolate from neighboring sample points rather than interpolate between them.
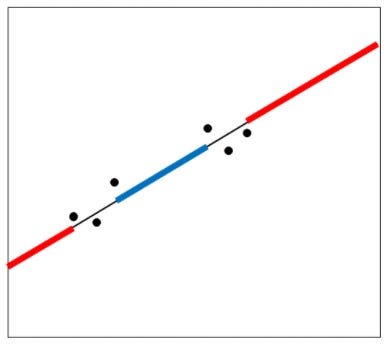
Extrapolation(red) Vs Interpolation(blue)
For a given training dataset, if our data points lie beyond/close to “the edge”, i.e., endpoints of the majority range of sample space, then the data points can be considered to be of extrapolating nature, and vice versa.
Why is extrapolation a problem?
Extrapolation is generally considered a concern as we are much less certain about the shape of the relationship outside the range of your data.eg.👇
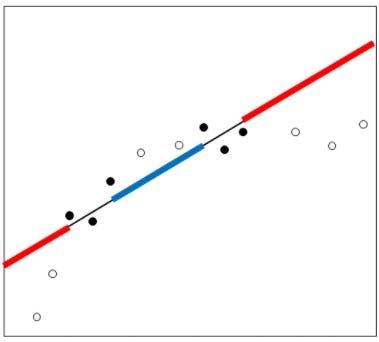
Unclear prediction for extrapolar points
The Curse of dimensionality
Generally, datapoints begin to become sparse as the dimensions of our sample space increase, which, increases the number of extrapolar points and also leads to overfitting.
Higher Dimensionality of Text Based Data
To understand why Text Based Data is considered higher dimensional, let’s imagine how we would featurize data
eg of text: ”Hey there, Welcome to this medium article”
So, a general way is to figure out the sentences’ bag of words, i.e., the list of distinct words and their frequencies for a given document.
So the bag of words here can be considered as:
hey:1
there:1
welcome:1
to:1
this:1
medium:1
article:1
To make sense of the given data, we need to consider each unique word as a feature, with it’s respective value being the number of times the word occurs.
Now the given text will be a part of a larger corpus(a group of sentences/paragraphs), which can go to another super-group and so on, hence bringing about the problem of high dimensionality.
In comes, Topic Modelling!!
Topic modelling is the practice of using a quantitative algorithm to tease out the key topics that a body of text is about.
We basically want to reduce our corpus features from about 100k features to around 10–20 topics or less.
The Implementation
Let us first make some example documents and compile them.
Now, we can preprocess the data.
We will remove the stop words(words like a, an, the) which have no inherent meaning.
We will also lemmatize the words(process of grouping together inflected forms of a word, so that they can be analyzed as a single item). eg: good, better, and best basically mean the same thing, i.e. point towards something being positive, so we can group them together.
Now, we can prepare a Document Term Matrix, which is a method to convert our text corpus into a matrix representation to better fit our model, which we’ll create in the next section.
We can now create and train our LDA(Latent Dirichlet Allocation) model, which is a generative statistical model allowing us to group our data into topics.
Now we print the output
The result:
Here, the corpus has been made into 3 main topics. Each line is a topic with individual topic terms and weights.
These topics can now be used to train and learn custom-made models with relative ease and less computation.
Github Link: https://github.com/NeelGhoshal/Topic_modelling
Feel free to contact me with anything at my social handles